A short overview of research interests goes here.
Working Papers
 Johnathan Sun, Andrei Shleifer, Yonatan Belinkov
Johnathan Sun, Andrei Shleifer, Yonatan BelinkovIn submission
Abstract
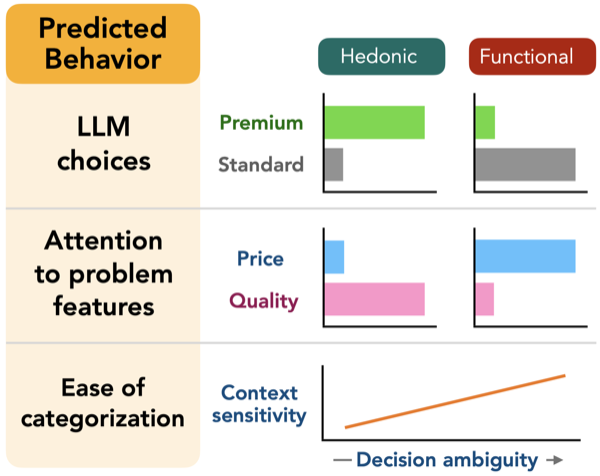
Large language models (LLMs) are increasingly deployed as decision-makers. LLMs exhibit a range of human-like choice behaviors, but whether these reflect human-like mechanisms or surface-level mimicry remains unclear. We evaluate whether a leading cognitive economic theory that grounds decision-making in problem categorization and attention allocation explains LLM context sensitivity. Across nine open-source and commercial LLMs on a novel 140,000-trial product choice benchmark, we find mixed empirical support: context induces human-like shifts in choices and categorization, but does not reliably reweight attention between features like price and quality. Neither scale nor chain-of-thought reasoning reliably attenuates context sensitivity or generates human-like behavior. These results suggest that LLM decision mechanisms are at least partially distinct from human ones.
 Johnathan Sun
Johnathan SunSenior Thesis. Thomas T. Hoopes Prize for excellence in undergraduate research.
Abstract
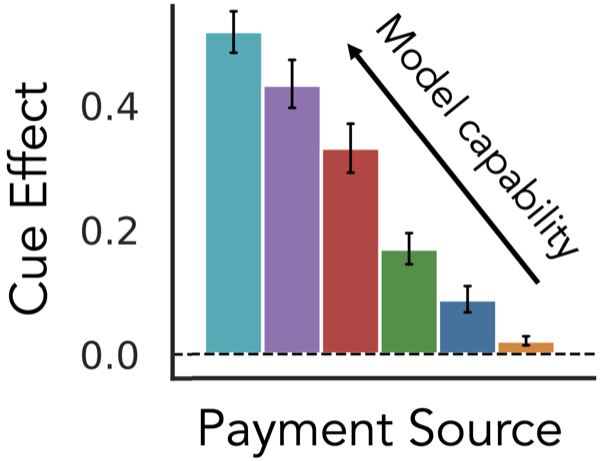
Large language models (LLMs) increasingly make consequential decisions on our behalf, but the underlying decision-making mechanisms remain poorly understood. One hypothesis is that LLMs decide like humans, but we find that even in simple choice problems, LLM and human decisions systematically differ in their sensitivity to context, such as whether a purchase is made online or in store. To explain this discrepancy, we develop the first LLM-specific theory of choice: while context alters the preferences of a fixed subject in leading human theories, it causes an LLM to update its belief about which subject it is interacting with.
Across six models and ten million trials, we find substantial context effects on LLM choice that increase with model capability. LLMs infer detailed user characteristics such as demographics and values from minimal context. Conditioning on these characteristics strongly attenuates context effects, indicating that inferred beliefs about the user mediate choice. This attenuation also collapses cross-model variation, implying that more capable models are more context-sensitive because they update beliefs more sharply. Our results suggest that researchers who increasingly treat LLMs as stand-ins for human subjects risk confounding treatment effects with shifts in the inferred subject. As models become full-fledged economic agents, we need to rigorously characterize LLM decision-making on its own terms.
Publications
 Johnathan Sun, Andrew Zhang
Johnathan Sun, Andrew ZhangICLR Workshop on AI for Mechanism Design and Strategic Decision Making
Abstract
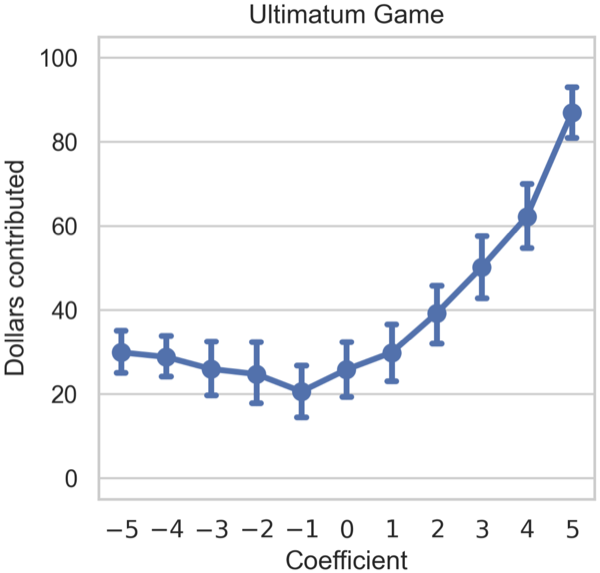
Large language models (LLMs) are increasingly deployed as autonomous decisionmakers in strategic settings, yet we have limited tools for understanding their high-level behavioral traits. We use activation steering methods in game-theoretic settings, constructing persona vectors for altruism, forgiveness, and expectations of others by contrastive activation addition. Evaluating on canonical games, we find that activation steering systematically shifts both quantitative strategic choices and natural-language justifications. However, we also observe that rhetoric and strategy can diverge under steering. Moreover, vectors for self-behavior and expectations of others are partially distinct. Our results suggest that persona vectors offer a promising mechanistic handle on high-level traits in strategic environments.
 Victoria R. Li*, Johnathan Sun*, Martin Wattenberg
Victoria R. Li*, Johnathan Sun*, Martin WattenbergIEEE Visualization (VIS)
Abstract
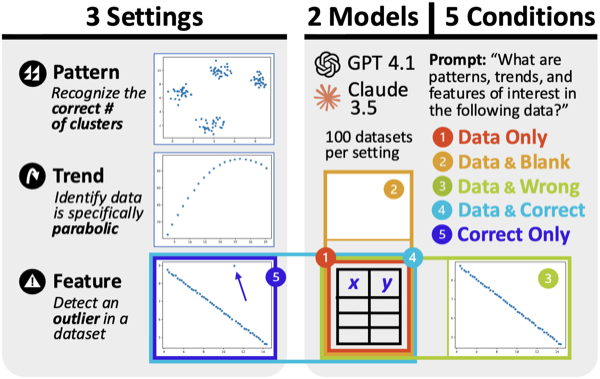
Charts and graphs help people analyze data, but can they also be useful to AI systems? To investigate this question, we perform a series of experiments with two commercial vision-language models: GPT 4.1 and Claude 3.5. Across three representative analysis tasks, the two systems describe synthetic datasets more precisely and accurately when raw data is accompanied by a scatterplot, especially as datasets grow in complexity. Comparison with two baselines — providing a blank chart and a chart with mismatched data — shows that the improved performance is due to the content of the charts. Our results are initial evidence that AI systems, like humans, can benefit from visualization.
Additional Research
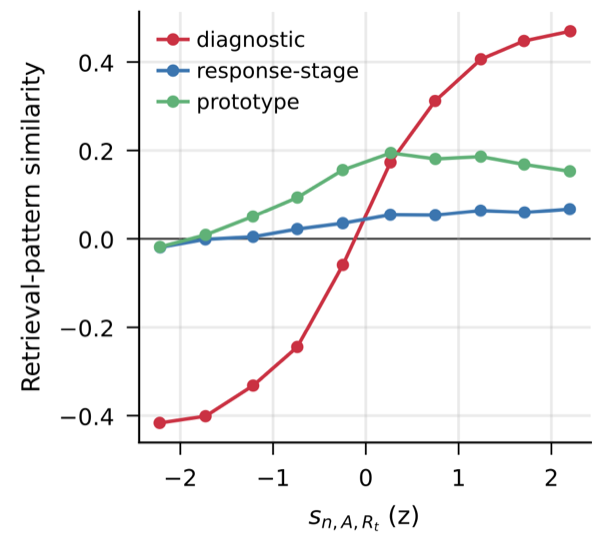 Johnathan Sun, Anya Mostek, Sofia Chen
Johnathan Sun, Anya Mostek, Sofia ChenAbstract
Probabilistic judgments about categories are systematically biased toward features that distinguish the category from a comparison class. We propose that this representativeness bias arises in the geometry of memory retrieval. Building on the key-query-value framework, we model category judgment as competitive retrieval where the query is constructed at retrieval time as a contrastive direction between target and reference categories, learned by a centered, category-gated Hebbian rule. The resulting softmax retrieval produces a covariance-law bias whose mean tilt recovers representativeness, We formally characterize this bias, provide a plausible neural implementation of this mechanism, and develop simulations that validate the predictions and dissociate diagnostic retrieval from prototype, availability, and response-stage accounts. These initial results suggest promising behavioral and neural experiments.
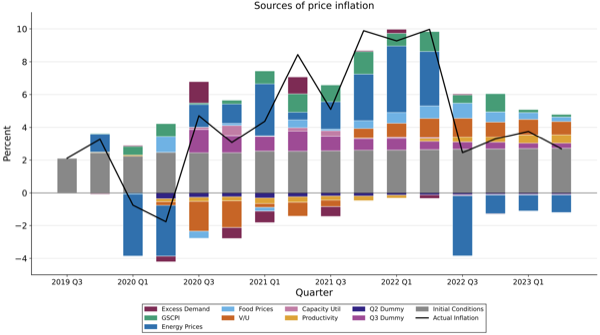 Jerry Liang*, Johnathan Sun*
Jerry Liang*, Johnathan Sun*Abstract
We extend the framework of Bernanke-Blanchard (2023) by specifying and estimating a dynamic model in which supply-side constraints evolve endogenously through short-run capacity limits and persistent shortages. In addition to prices, wages, and inflation expectations, the model allows shortages to respond to past shortages and to excess demand when nominal spending rises relative to productive capacity. This structure enables us to trace the dynamic interaction between demand, supply bottlenecks, and labor-market conditions and to quantify their respective contributions to U.S. pandemic-era inflation.
We find that, as in Bernanke-Blanchard, even after endogenizing shortages and allowing demand to affect prices through capacity constraints, most of the inflation surge beginning in 2021 still reflects shocks to prices given wages rather than direct wage pressure from overheated labor markets. Endogenizing supply dynamics reveals that supply-chain disruptions were the dominant source of these price shocks, generating persistent shortages in the presence of short-run capacity limits. Excess demand associated with tight labor markets contributed to inflation primarily through its effects on shortages early in the pandemic recovery, while its influence later in the sample operates increasingly through nominal wage growth.
While labor-market tightness was not the primary driver of the initial inflation surge, its effects— transmitted first via shortages and subsequently via wages—are more persistent than those of transitory price shocks. These findings suggest that restoring price stability requires not only moderating aggregate demand but also alleviating supply-side constraints that propagate inflation when short-run capacity limits are strained.
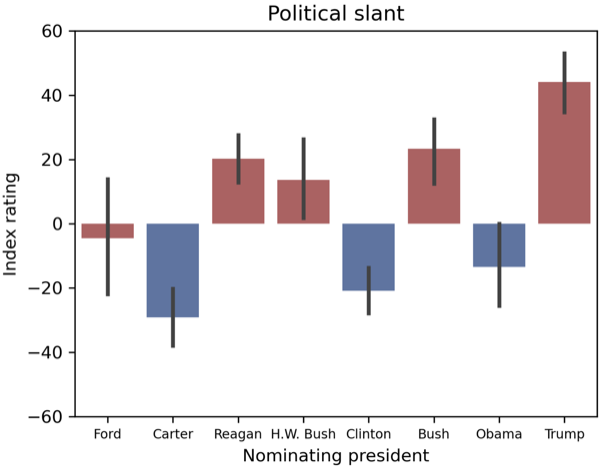 Johnathan Sun
Johnathan SunAbstract
We introduce a large language model method for measuring judicial ideology and rhetoric in abortion jurisprudence. Drawing on a corpus of 310 abortion-related opinions from the US Federal Courts of Appeal (1990-2024), we use GPT-4o to rate each opinion along indices capturing support for abortion access, abortion-related speech, broader political slant, and deference to precedent. Rratings reveal sharply partisan differences by nominating president and party, a steady rightward and polarizing shift in the federal judiciary over time, and a Trump cohort that is the most conservative and ideologically consistent in the sample. Further analysis shows that opinion type and panel composition shape how judges write, with dissents scaling almost one-to-one against majority opinions. We argue that LLM-assisted rating offers a scalable new tool for analyzing expert legal text and other corpora in social science research.
 Robin Greenwood, Richard Ruback, Johnathan Sun, Robert Ialenti
Robin Greenwood, Richard Ruback, Johnathan Sun, Robert IalentiHarvard Business School Case 224-051
Abstract
The American Bully XL, first introduced to the United Kingdom around 2014, had been held responsible for a disproportionate share of both dog-related attacks and deaths. The case discusses the announcement, in October 2023, that the dog breed would be added to a list of banned dogs under the Dangerous Dogs Act. The case allows for a discussion of how society regulates risks, particularly related to products or activities that might result in personal harm or harm to others. The case also provides international comparisons of animal regulation, and potential issues resulting from the ban.